2026世界杯押注app官方版 牛津、英伟达等提议操心压缩新范式: 老师时让模子学会断舍离


剪辑|Panda
2026 年头,各大 AI 厂商在高下文窗口长度上张开浓烈角逐。Google 的 Gemini 3 Pro 已接济 100 万级 token 高下文,Meta 的 Llama 4 Scout 更宣称可处置 1000 万 token。GPT-5 系列也在快速鼓动长高下文才略。
按这个趋势,今天的大模子照旧粗略连气儿读无缺套《哈利・波特》,将来以致可能平直分析总计大型代码仓库。
但数字背后也荫藏着一个重要问题:高下文越长,模子就越「记不住」。
这并非模子不够智慧,而是 Transformer 架构自己的工程不断。当模子处置长文本时,需要为每个 token 保存 Key-Value(KV)气象,用于后续生成时的堤防力规画。这个缓存区域被称为 KV Cache。
KV Cache 的大小会随高下文长度线性增长:输入越长,占用的 GPU 显存越多,推理速率也越慢。关于百万 token 级别的输入,在大型模子和高精度推理场景下,KV Cache 的内存支出可达到数十到数百 GB,远超单张顶级 GPU 的显存容量。
高下文窗口的竞赛,内容上是一场显存的战斗。
靠近这一窘境,计划者们照旧开采出多种「过后压缩」决议,也等于在模子老师完成之后,用各式算法对 KV 缓存进行精简。这些步调确乎有用,但它们都遗漏了一个更根底的问题:淌若模子在起头学习的时辰,就莫得被教育去生成「容易被压缩」的里面示意,那么后期非论若何压缩,后果都将受到天花板适度。
就在这一配景下,来自牛津大学、以色列理工学院、AITHYRA 和英伟达的趋附计划团队提议了一个新的念念路:与其过后弥补,不如老师时就让模子主动学会「压缩友好」的操心花式。

他们将这套步调定名为 KV-CAT(KV 压缩感知型老师,KV-Compression Aware Training)。

论文标题:Training Transformers for KV Cache Compressibility
论文地址:https://arxiv.org/abs/2605.05971
KV 缓存为若何此难压缩?
要贯串这项计划的价值,先得弄廓清一个直观上看似奇怪的事实:两个输出都备换取的模子,其 KV 缓存可能一个极易压缩,另一个根底无法压缩。
这听起来很反直观。咱们频频以为,淌若两个系统的「收尾」换取,它们的里面过程应该莫得内容区别。但在神经网罗宇宙里并非如斯。
计划团队用一个陋劣的例子来施展这极少:「词频统计」。给模子输入一段笔墨,让它统计每个字母出现了几许次。这是一个只依赖「汇总信息」的任务,与每个字母出现的轨则无关。
雷同完成这个任务,不错有两种截然相背的里面已毕花式。
第一种是「当关联词然」的已毕:模子对每个 token 进行脱落编码,终末通过堤防力机制对总计 token 作念平均,得出统计收尾。这种步调陋劣平直,LOL比赛下注app2026中国官方下载但存在一个致命劣势:任何对 KV 缓存的压缩都会冲突平均规画,导致最终收尾出错。计划团队从数学上施展注解了:这种已毕花式,在表面上对任何进程的压缩都不具备容错才略。
第二种是「结构化」的已毕:模子在处置每个 token 时,迥殊纪录序列的位置信息(即这段前缀有多长),当 KV 缓存被压缩成一个单一的向量时,模子不错愚弄位置信息对压缩后的汇总值进行从头校准,从而复原正确的统计收尾。这种已毕花式,表面上不错将自便长度的前缀压缩到仅剩一双 KV 向量,同期保握零误差。
两种已毕,换取的输出,截然相背的压缩性。
重要在于:表率的模子老师过程,都备莫得激发让模子去选用第二种更结构化的已毕。因为在莫得压缩的场景下,两种花式后果都备一样,老师信号无从差异。
中枢步调
让模子在「戴着桎梏」的情况放学习
意志到这极少后,计划团队打算了 KV-CAT 老师决议。中枢念念路极为平直:淌若你想让模子学会在 KV 缓存被压缩的情况下正常责任,就在老师时模拟这种压缩压力。
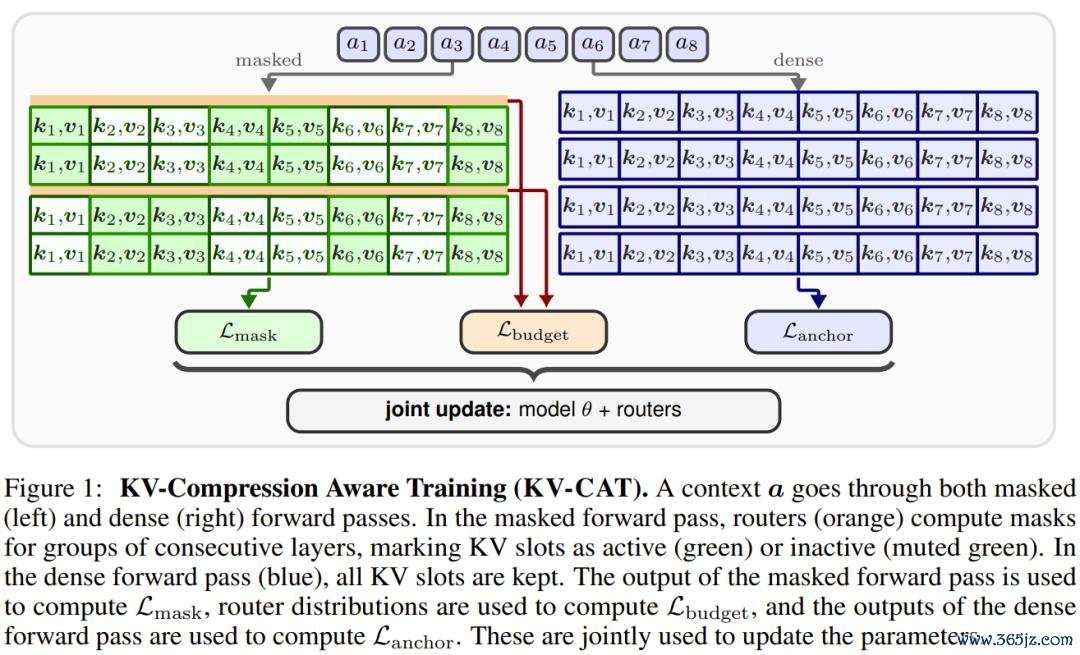
这雷同于一种「操心禁绝老师」。平常的模子老师就像让学生在磨砺时不错带着无缺的条记本作答 —— 虽然发扬优异。而 KV-CAT 则是在老师时就充公大部分条记,2026世界杯中国最新押注app逼着学生将最遑急的信息内化成信得过的「贯串」,而非对条记的依赖。
具体来说,KV-CAT 在原有的预老师模子基础上,引入了一组轻量级的「路由器」模块。这些路由器在老师的每一步会动态判断哪些 KV 槽位是必要的、哪些不错被屏蔽,观念是保留约 50% 的 KV 缓存。每次前向传播,模子需要同期进行两次规画:一次是正常的「全量」规画(通盘 KV 槽位都可见),一次是「压缩」规画(仅保留路由器选中的 KV 槽位)。
老师观念由三部分构成:
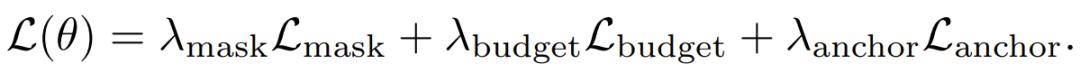
自蒸馏弃世,让压缩模式下的输出尽量迫临全量模式下的输出;
锚定弃世,平直对全量模式施加表率的下一个词计划观念,确保模子的基础才略不退化;
预算弃世,不断路由器本质保留的 KV 比例不偏离 50% 的观念太多。
总计经由完成后,路由器模块在推理时会被关闭。输出的是一个表率的 Transformer 模子,它的参数与原模子换取,但其里面照旧被老师成一种「自然压缩友好」的示意格式。后续不错搭配自便现成的 KV 压缩步调使用。
详备的数学神志请探望原论文。
实验收尾
全面卓越,且不以基础才略为代价
计划团队将 KV-CAT 应用于 Qwen2.5 的两个规模版块(0.5B 和 1.5B 参数),并在多个维度上对其进行评估。
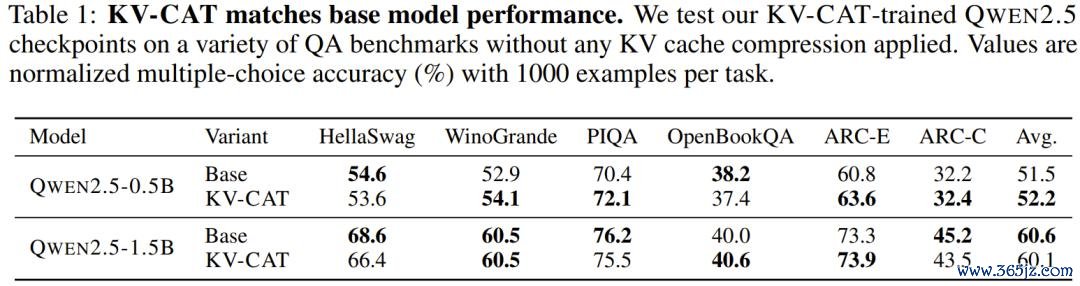
起头,基础才略莫得弃世。 这是最重要的考证。在六个表率多选题基准测试上(包括 HellaSwag、WinoGrande、ARC 等),KV-CAT 老师后的模子与原始模子的确握平:0.5B 版块平均提高了 0.7 个百分点,1.5B 版块平均下落了 0.5 个百分点,均属于正常的老师波动范围。这施展 KV-CAT 莫得以糟跶通用才略为代价换取压缩性能。
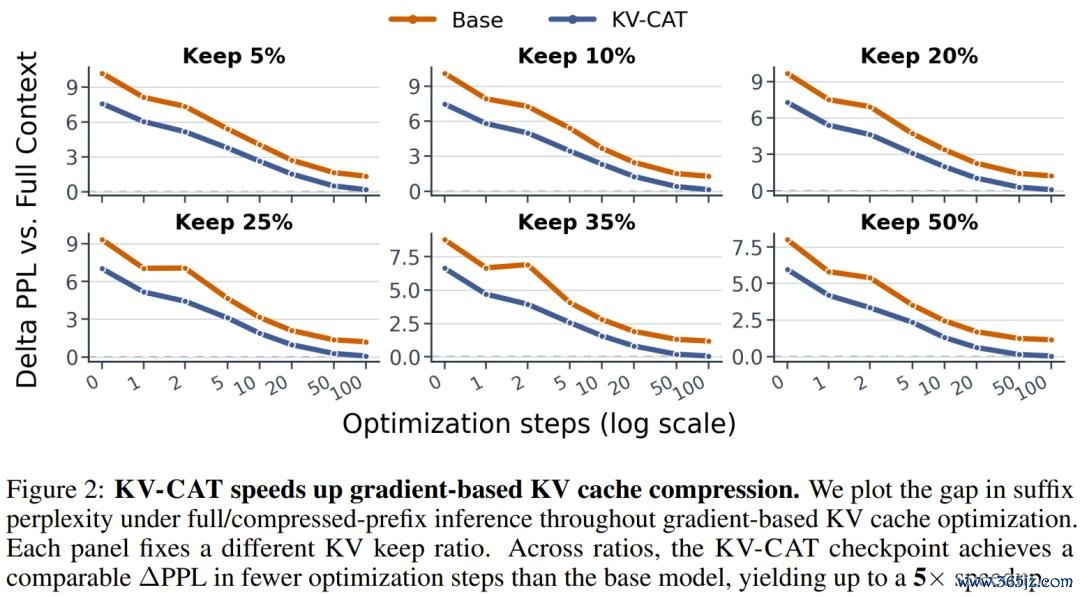
其次,后期 KV 压缩的后果大幅改善。 在同等压缩预算下,与原始基础模子比较:
使用堤防力匹配(Attention Matching)步调对前缀进行压缩后,续写文本的困惑度(perplexity)差距最多削弱了 3.21 倍 —— 也等于说,压缩后模子的发扬与压缩前更为接近。
使用梯度优化法进行压缩时,KV-CAT 模子达到换取压缩质料所需的优化步数减少了最多 5 倍。这对本质部署至关遑急:压缩自己也需要规画资源,淌若压缩速率更快,就意味着不错处置更多肯求。
第三,「大海捞针」检索准确率显贵提高。 计划团队打算了一个经典的长文检索测试:在一段充满烦躁项的长文本(约 1024 个 token)中藏入一个六位数的「密码」,然后将文本的 KV 缓存压缩后,测试模子能否正确回忆出这个密码。
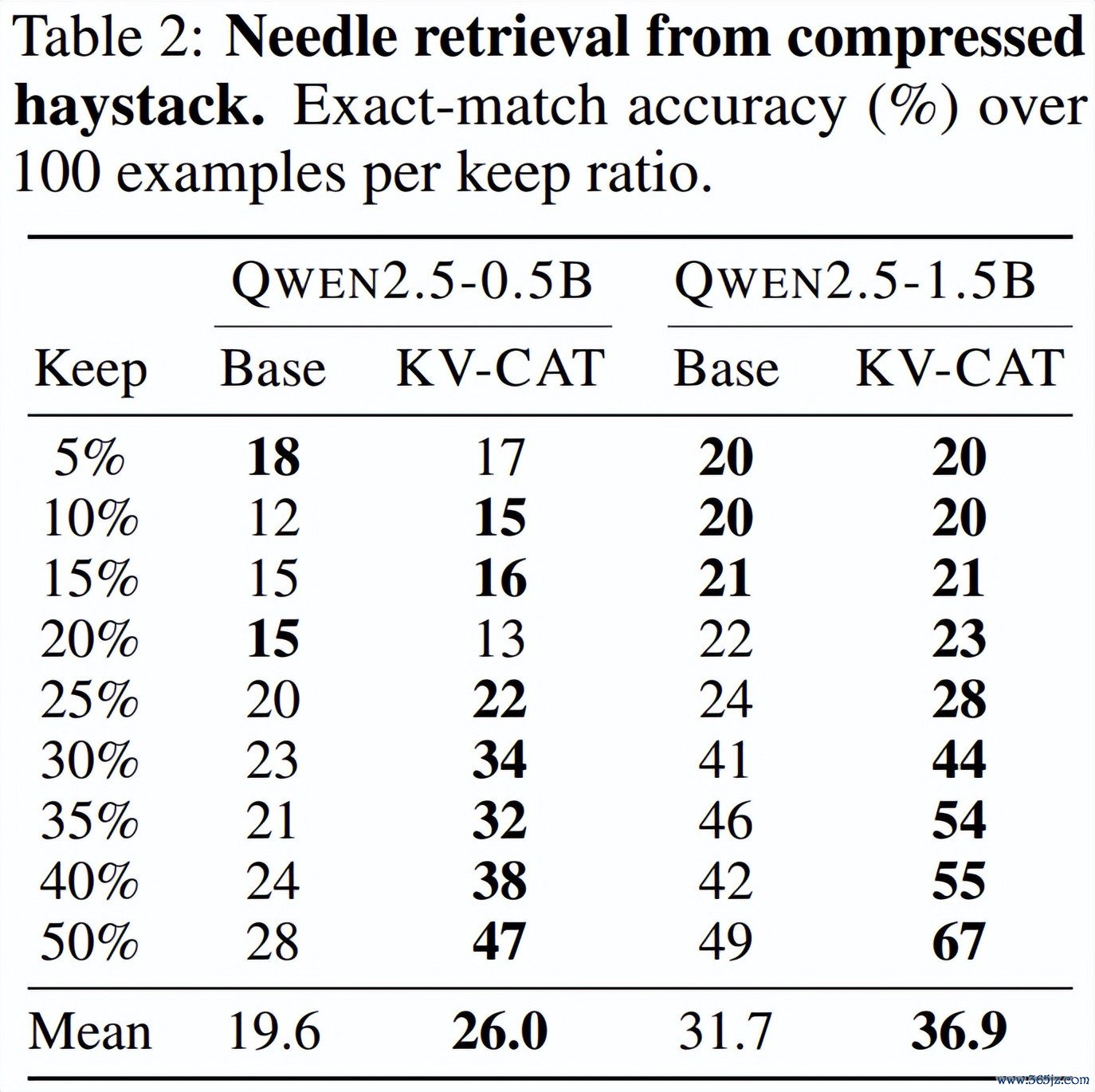
在保留 50% 的 KV 槽位的情况下,KV-CAT 版块的 Qwen2.5-0.5B 检索准确率从 28% 跃升至 47%,Qwen2.5-1.5B 则从 49% 提高至 67%,提高幅度接近 68%。即使在极点压缩(仅保留 10% 的 KV)的情况下,KV-CAT 版块的性能也与基础模子在轻度压缩时相称。
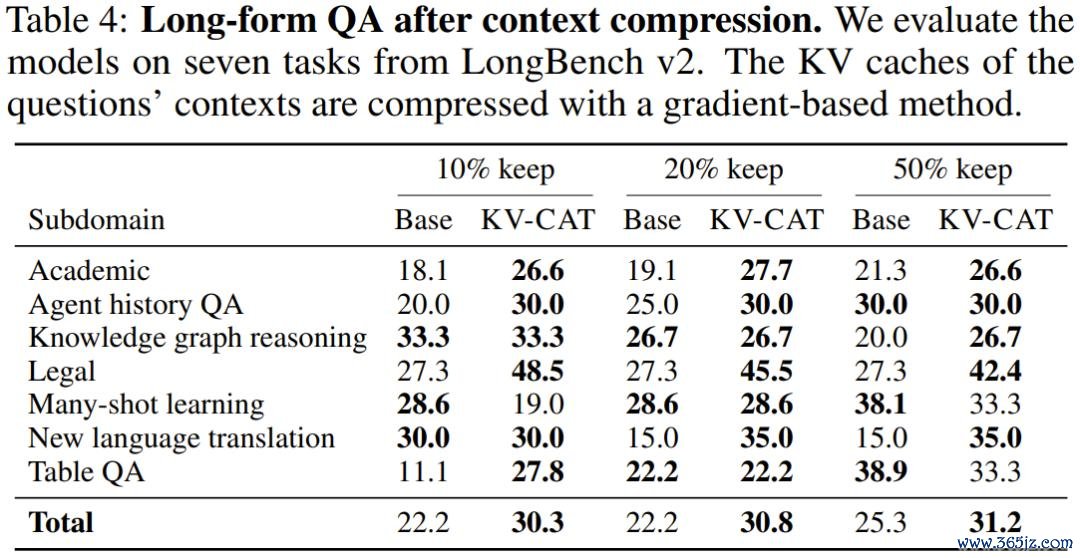
第四,长文问答任务也有彰着改善。 在 LongBench v2 的七项长文本问答任务上,KV-CAT 模子在各压缩比例下的平均准确率均高于基础模子,最大提高幅度达到 39%。
结语
KV-CAT 并不宣称要取代现存的压缩算法。计划团队明确指出,它的观念是成为现存压缩步调的「底层增强」:雷同的压缩算法,作用在 KV-CAT 老师过的模子上,后果更好、速率更快。
这种「老师时为推理作念准备」的念念路,在 AI 系统工程领域并不生分。但将其具体应用于 KV 缓存的可压缩性,并从表面上施展注解这种属性都备由模子的学习示意决定,是这项责任的中枢孝顺。
虽然,这套决议也有其代价:连续预老师引入了迥殊的老师支出,路由器模块增多了已毕复杂度,现在的实验规模也仅限于 0.5B 和 1.5B 两个相对微型的模子。计划者坦承,这套步调能否平滑推广到百亿以致千亿参数的大模子,仍是一个洞开问题。
但这一标的的逻辑是设置的。跟着高下文窗口的竞赛不竭鼓动2026世界杯押注app官方版,显存瓶颈正升级为制约 AI 系统规模化部署的中枢挑战。让模子从一初始就「学会压缩」,而不是生成了难以压缩的示意之后再一火羊补牢,将是将来大模子老师工程中越来越值得醉心的打算维度。
 备案号:
备案号: